万物赋能:边缘计算与人工智能交融使能
发布时间:2020-06-17 11:21 来源: 边缘计算社区
边缘智能:无所不在的智能协同
边缘智能依托于边缘计算的低时延、分布式的特性,实现了将人工智能的自主学习、智能决策能力进行下放。
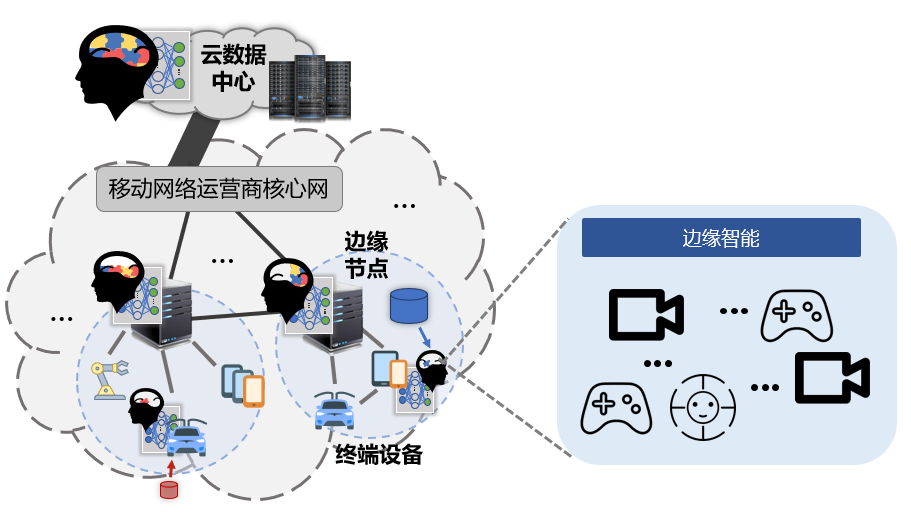
图1-边缘智能示意图
如图1所示,边缘智能基于边缘计算的运行机制和网络结构,为智能应用提供多层次的资源支持和性能优化,而边缘智能对智能应用的优化和保障主要体现在以下三个方面。
第一,优化智能应用请求的响应时延与资源供给。
目前传统的网络架构采用了基于云计算的执行模式,通过将人工智能服务部署在云端,依托于云端服务器集群丰富的硬件资源来处理计算请求。这虽然解决了硬件资源不足的问题,但云端服务器地理位置偏远的特性造成了额外的时延,导致基于云计算的架构无法满足实时服务的需求。可通过引入边缘计算技术来支撑人工智能服务,在网络边缘分布式部署大量的边缘节点,从而向资源受限的终端设备提供支持来实现边缘智能。
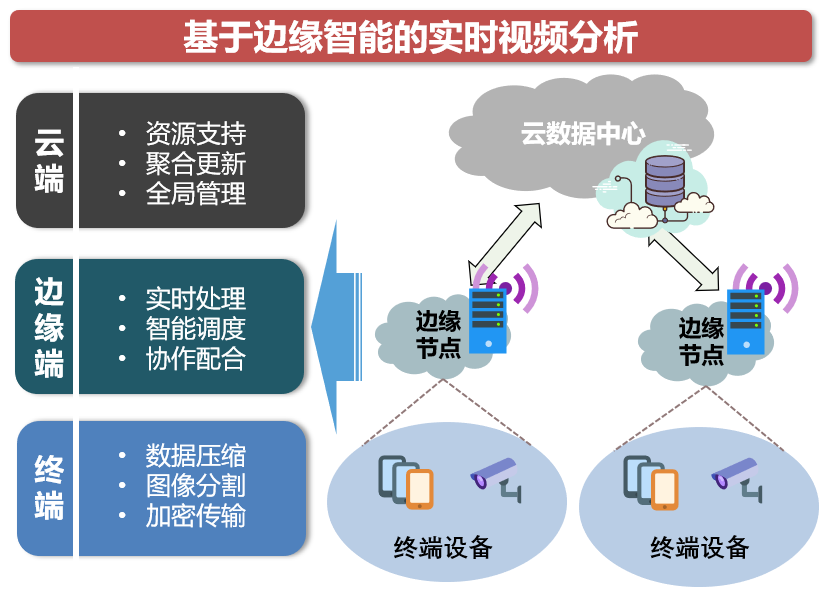
图2 实时视频分析解决方案
边缘智能已经在许多应用领域有了优异的表现,如图2所展示的边缘智能在实时视频分析中的应用,实时视频分析在智能工厂、智慧社区、无人驾驶等场景中都是不可或缺的关键环节,借助边缘智能实时视频分析可以更加智能、更加高效。在实时视频分析服务的应用过程中,智能手机、智能摄像头等资源受限的终端设备在捕获视频数据之后,若无法支撑人工智能服务高额的资源消耗,智能终端可以仅执行数据压缩、图像分割等预处理,然后将数据传输至边缘节点处理。
数量众多的边缘节点一旦接收到来自终端设备的服务请求后便立即开始处理,并且在边缘端还可以进行多个边缘节点之间的智能协作以提供更好的服务。当边缘端无法满足应用的资源需求时,可以将数据传输至云端处理,但也会不可避免地造成额外的传输时延,这也是未来需要解决的问题之一。
此外,云端除了提供强大的资源支持之外,还能为边缘端提供人工智能模型的聚合更新能力,从而帮助边缘节点对全局知识进行学习和训练。
综上所述,基于边缘智能可以将视频分析服务部署在更接近请求源的边缘节点上,相对于云端的远距离连接,边缘节点低传输时延的特性可以实现视频分析请求的实时处理,促进应用服务的敏捷响应,而对于边缘智能中的计算密集型任务请求,则可以通过将其传输至云端来满足高额的资源需求。
第二,改进智能应用数据的通讯传输与隐私保护。
由于在边缘计算平台中通常需要大量设备的协同运行,因此不同设备之间不可避免的存在大量数据传输,这不仅会给通讯网络造成极大的流量负载,还会使得数据缺乏隐私性保护。因此联邦学习被进一步提出,它使得人工智能模型在边缘计算架构中可以进行分布式训练,并且无需上传样本数据,只需将训练后的参数更新上传,之后再由边缘节点聚合参数更新并进行参数下发。

联邦学习在边缘计算的应用赋予了人工智能模型分布式训练的能力,使得智能设备可以在本地对数据进行处理并仅对参数的更新信息进行传输,避免了集中式训练时需要将大量原始数据传输汇总的方式,从而进一步保障了人工智能模型的训练过程,在实现了减轻流量压力的同时,强化了数据的隐私保护。
第三,提升智能应用服务的应用拓展与部署保障。
在人工智能服务的应用实践方面,目前国内外已经有多种边缘智能平台发布并投入使用,这进一步拓展了人工智能服务应用的广泛性,而多样化与有价值的人工智能服务能够拓宽边缘计算的商业价值,为边缘智能的实现提供了基础和保障。
华为公司在2018年设计并推出了边缘智能平台IEF,可以将云端服务器的处理能力延伸至边缘侧,从而就近提供实时的智能服务。此外,IEF还通过兼容kubernetes以及docker实现了轻量化的特性,并且依托于边云协同的特性在监控平台、智能工业等领域有着良好的前景规划。
2019年,百度公司宣布开源了其边缘智能计算平台BAETYL,能够提供身份制定以及规则策略制定、云端管理下发、边缘端部署运行等功能,并且平台采用了模块化思想,实现了用户按需使用的模式。此外,BAETYL还可以与百度边缘智能管理套件(Baidu-Intelli Edge)协同使用,进一步推进边缘智能的发展。
AWS Greengrass是由亚马逊公司在2017年发布的边缘智能平台,它使得设备可以在本地对数据进行处理以及数据筛选,从而只对必要信息进行传输,极大地提高了信息传输效率。此外,AWS Greengrass还具有优异的鲁棒性(Robustness),可以在设备间歇性网络连接的情况下使用,能够适应更加复杂的网络环境。
2018年,微软公司将其边缘智能平台Azure IoT Edge作为开源项目开放提供,这一平台采用了容器的方式运行,容器中不仅支持微软提供的相关服务,也支持用户提供的代码并且提供了对容器的监控管理功能。
智能边缘:无所不能的数字演进
智能边缘的目的即是将人工智能算法融入边缘以支持动态的、自适应的资源分配与管理。
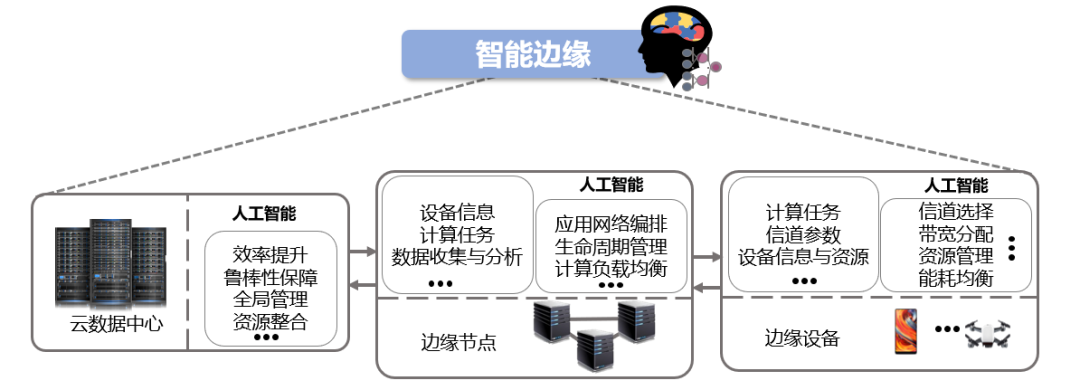
图3 智能边缘示意图
如图3所示,智能边缘通过使用人工智能的学习和决策能力来实现对边缘计算平台中的资源、设备、请求的智能化管理,来优化提升边缘计算平台的运行效率,而智能边缘对于边缘计算的优化主要包括以下三个方面。
第一,实现边缘计算平台的动态管理与高效运行。网络中往往包含大量异构设备以及种类繁多的应用请求,因此,如何针对不同的应用请求特性,实现异构设备的自适应协作处理就成为了一个棘手的问题。目前有许多处理这类问题的传统算法,如贪心算法、蚁群算法等。然而,这些传统算法却存在许多弊端:一是对网络环境变化以及异构硬件参数的适应性差;二是缺少对长期收益的考虑;三是优化指标相对单一。
因此,传统算法已经无法适应边缘计算平台的性能发展需求,要实现性能瓶颈的突破就必须探索和应用具有高效性、实时性、动态性的决策算法,而人工智能技术出色的决策能力可以帮助边缘计算平台实现智能化管理。
边缘计算平台往往采用端—边—云的多层组织架构,所以如何在不同组织层面中的异构设备之间进行高效的计算卸载调度成为必须考虑的问题,而人工智能技术可以通过计算卸载决策实现将不同层面的异构设备牢牢结合在一起。智能决策模型一般通过与网络环境的不断交互进行反复迭代来不断提升决策的准确性,但网络环境的复杂性和动态性会导致规模庞大的状态空间。

第二,决策边缘计算任务的计算卸载与协同处理。如图4所示,智能边缘可以依据计算任务不同的特征和属性来自适应地选择执行模式。对于计算需求较小的任务可以直接在终端设备执行,从而避免数据传输所导致的时延以及资源消耗。然而,对于资源需求较大的计算任务,可以通过人工智能模型对边缘计算平台中进行智能化管理,从而充分整合利用平台中异构设备的资源实现任务的协同高效执行。
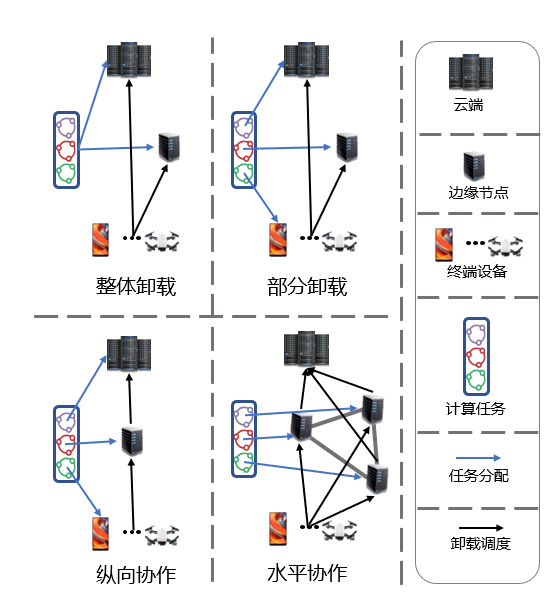
图4 智能边缘中任务执行模式
对于任务卸载可以划分为整体卸载与部分卸载两种模式。整体卸载会将传输至单一边缘节点或云端执行,这可以避免对任务进行分割整合所造成的资源消耗,但当计算任务规模较大时,将任务传输至单一设备执行会导致执行效率低下,可以选择对任务进行分割再交由不同的设备执行处理,通多不同设备的协同处理实现异构设备资源的利用整合。
此外,根据边缘计算平台中的协作方式还可以进一步分为纵向协作与水平协作。纵向协作将会联合端—边—云三层的异构设备来协同处理计算任务,由于不同层级的设备资源存在差异会导致人工智能服务性能的差异,通过多层级的协作可以实现对计算任务的各个环节按需供应。水平协作则通常将任务交由若干个边缘节点处理,通过在单一层级中对计算任务进行协同处理,可以在充分利用设备资源的同时,减少通讯传输造成资源消耗。
第三,降低边缘计算数据的冗余传输与低效存储。无论是现在还是未来,数据传输的压力只增不减,但不是所有的数据都是有用的,所以为了减少应用服务中的冗余数据传输、实现应用服务的敏捷响应,边缘缓存的设计也加入了边缘智能化的大集体。边缘缓存方案可以通过在边缘节点缓存热点内容,实现在出现相关请求时能够快速响应。因此,基于边缘缓存技术可以对同一地区中的相似请求进行快速响应,从而避免了对请求的数据进行多次冗余传输的情况。
然而,边缘缓存却面临着一个严峻挑战,由于边缘节点的存储空间具有局限性而且其服务范围内的热点内容难以预测,因此,无法实现缓存的高效命中。这时,人工智能依然发挥着重要作用,它可以依据每个边缘节点的服务内容进行定制化的策略设计,并可以追踪热点内容的实时变化来对策略进行智能化调整,从而确保缓存内容的有效性和准确性。因而,借助人工智能技术自主化的决策设计边缘缓存方案,可以避免相似请求的冗余数据传输以及促进存储空间的高效利用,实现缓存命中率的大幅提升。
总结与思考
世界每时每刻都在产生数据,就像每天的温度、湿度,甚至于一棵不起眼的草的颜色深度……这些诞生于物理世界的数据,本身只是一堆冰冷的数字,在我们使用相关的工具、(如温度计、传感器等)对其测量之前,这些数据对我们人类而言没有任何的价值。
世界上产生的数据每年都在以指数规模增长,最好的处理方法就是将70%的数据都在网络边缘进行处理,通过分散的方法减轻计算压力;另外,这些由设备产生的数据中有太多对我们无用的数据了,据思科统计,到2021年结束,全球每年产生的数据将会达到847ZB,而在这样海量的数据中仅有约10%的数据才是有用的。
这些数据在还没有与人类世界产生联系时,它本身还不能算作是信息。但通过打破数据算力壁垒,将物理世界中冰冷无意义的数字、冗余海量的数据抽取出来,映射到数字空间,形成可演算的、对生活进行调整与反馈的知识,信息就由此诞生。算力边界的突破需要借助一系列的智能算法如特征工程和知识整合的支撑。数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。这些原本复杂冗余的数据被精简为一条条的知识进而映射到数字空间,知识的相互作用关联,形成真正有价值有意义的信息,开始与人类世界产生联系(见图5)。
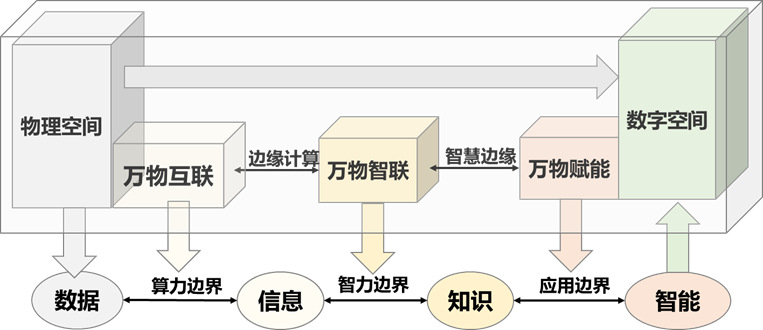
图5 从万物互联到万物智能
当有人类行为参与到信息鉴别与利用时,这些信息才终算突破了智力边界,在人类与信息的交互过程中,通过智力来选择这些对我们有利的信息,让有用的信息及时反馈到我们的行动中去,避免进行不利的活动。
例如,从事同样的农耕活动,古时的完全靠人力耕作,后来依托工具以及使用耕牛,再到如今的机械化智能化的农业。虽然都是同等的工作,但这中间缺隔着巨大的智力鸿沟,这就是智力边界。所以,认知层边缘计算所面临的主要任务是如何更好地将人的智能与边缘算法相结合,从而提升边缘侧的算法效率、算法适配性,优化信息组合的结构,使这些信息更高效、快速地为人类所用,同时将作用的结果反馈给人类,辅助人类进行决策,形成人类认知层的边缘计算。
当智力边缘被突破,数据与信息随着人类的认知被更好的利用,激增的有益信息随着人类的社交网络被不断传播,如个人向朋友分享自己喜爱的事物可以增进朋友间的友谊等,当个人的分享需求越来越多,这种聚集的需求突破了应用边界,就形成了我们所熟知的社交网络应用。应用边界的突破一定程度上依赖于人的社交关系,主要存在两个相关的现象:社会信任(social trust)与社会互惠(social reciprocity)。
社会信任是指人与人之间的信任关系,普遍存在于亲人、朋友、同学之中。社会互惠是指在人类社会中存在的多个个人或团体通过相互合作从而达成目标最大化,各方都有收益的现象,普遍存在于同事、公司之间。一般来说存在这两类社会关系的人群更容易在用户与用户之间形成直接的内容分享,人类的这种行为就在社交边缘边界上搭建了一座沟通的桥梁,使得这些个人社交的边缘计算需求聚集形成了一种边缘计算应用从而达到智能边缘。
最终在实现这样的边缘智能应用场景之后,可以继续对这些边缘计算应用的场景进行优化与结构调整,通过模型共享、迁移学习等,用从一个环境中学到的知识帮助完成新环境中的学习任务,做到举一反三。在模型分享过程中我们将不断地调整原来应用的架构,进行持续的更新与发展,最终突破架构边界的限制。那时,我们将能够最大限度地去探索这一类人的社会行为背后的最大价值与意义,这些本质的价值与意义一方面作用于互联网服务提供商,他们可以在此基础上调整他们的边缘计算的服务核心,另一方面这些本质的价值也反馈于用户自身,实现自身的价值,展现最终价值层边缘计算的核心要义。
从算力世界中数据的海洋,到集合着成千累万信息的数字空间,再到人类智力对信息处理的参与,最终到达智慧边缘计算,用智能的、高效的方式最大限度地处理信息并反馈给人类,这条路似乎还有着无尽的绵延。但无论技术怎样发展,这些数据都会从人类和世界中来,最终也必然被运用于人类对世界的认识和改造中。
从万物互联到万物赋能,科技的发展带来了人与世界、人与人、人与自身关系的改变,还带来了对科技发展进行哲学思考的要求。在未来,既然智慧边缘计算将人类从琐碎的脑力消耗中解脱出来了,那么人类就需要用思维完成更重要的任务:既需要研究在科学发展的历程中人类如何认识科学,还要反思处于发展潮流中的人们是如何存在和认识自己的,从而推进人类—社会—科技—自身的和谐关系,这也为未来科学技术哲学的发展提供了方向和动力。
声明:本站在转载文章时均注明来源出处,转载目的在于传递更多信息,未用于商业用途。如因本站的文章、图片等在内容、版权或其它方面存在问题 或异议,请与本站联系(电话:020-37784831,邮箱:edit@fly-tech.com.cn),本站将作妥善处理。
推荐阅读





