一文看清光场技术的真相,为啥阿里谷歌都爱它?
发布时间:2017-12-15 11:41 来源: 青亭网
近日,专业光场影像公司Lytro推出了全新的光场摄像机Immerge 2.0,今年年初, Lytro还曾在D轮融资中获得了6000万美元的资金。光场技术一直被认为是一种终极的影像技术,Magic Leap著名的「魔法之跃」演示更是被奉为黑科技。

对于光场这个名词,大家应该都有所耳闻。它到底是何方神圣?为何有如此大的魔力?今天我便来为大家盘盘它的道,探探它的底。
光场的概念,其实真没什么复杂
我们生活在一个充满光线的世界,无论来自太阳还是人造光源,光线在我们周围沿着每一个方向传播,形成一个连续的光场。
简单来说,光场就是整个三维空间内所有的光线。如果能将光线的传播过程记录下来,并且能在显示端还原,就是完整的光场技术。
描述光场的全光函数是麻省理工学院教授阿德尔森(E.H.Adelson)于1991年提出的一组7维函数,其中包含任意一点光线的三维坐标(x, y, z)、任意传输方向(α, β),以及光的波长(λ)和时间(t),也就是P(θ,φ,λ,t,Vx,Vy,Vz)。
看到这里,也许有朋友已经产生了眩晕:三维坐标我懂,传输方向我懂,波长和时间我也懂,为啥合到一起我就不懂了呢?后边那个P(θ,φ,λ,t,Vx,Vy,Vz)是个啥玩意儿?
其实不光你们看着晕,我解释起来更晕。史蒂芬•霍金的《时间简史》中有一句话:「这本书中的每一个数学公式都会使书的销量减半」。我完全可以想象,如果后面再来几段傅里叶切片之类的方程,估计你们就都退票去了。真叫人头大……

幸好,我们不接触这些奇怪的数学公式,也可以理解光场的基本原理。不就是上面那个七维的函数不爽么?我跟你讲(gang)哈,其实不光咱们看着不爽,研究光场的人也一样不爽,相机和计算机就更不爽了。如果按照这个函数来采集光场,数据规模会过于庞大和复杂,无论是采集、存储、解算都非常困难,所以已经有人提前一步把它干掉了。
在1995年,北卡罗来纳大学的麦克米兰(McMillan)提出了一种简化函数。在数字影像中,波长(λ)可以直接通过像素颜色表示,时间(t)则可通过画面帧的变化来体现,因此我们实际上只需关注光线的位置和传播方向即可。新的简化函数只包含三维坐标(x, y, z)和光线仰角及方位角(θ,φ),将定义光场所需的属性从七维降低到了五维。
而由于光线在实际空间中传播时只要不被遮挡,其辐射度就不会改变,因此这个五维函数可以将表达纵深信息的z值舍弃,进一步精简为四维函数。在这种表示方式中,分别用两个平面上的一个点来确定光线经过的路径,这样一来光线的方向和位置就都可以确定了。
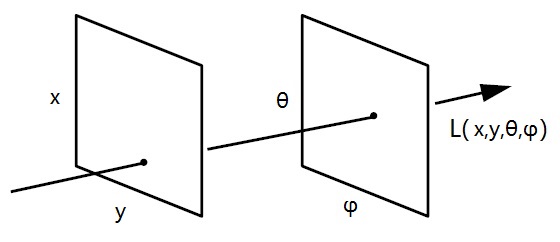
好了,现在光场已经被充分简化成了光线「从哪里来,到哪里去」的问题。为了不让这难得的简化成果付之东流,下面的内容里将不再出现任何数学公式,白话科普现在开始。
传统影像采集方式
我们知道了光场的基本概念,那么就有一个现实的问题摆在眼前:有没有某种神奇的影像设备,可以将三维空间中的光场信息直接采集下来呢?
很可惜,这和我们小时候用被窝收集阳光不会成功一样,能直接采集光场信息的高大上设备,在人类捉到野生哆啦A梦之前是不会出现的。
Why?我们先来回忆一下初中物理中的光学知识。
当一个苹果摆在我们面前时,光线从四面八方照射到它表面的各个位置,又从它表面的各个位置反射到四面八方。我们能看到它,是因为一些光线进入了我们的瞳孔,投影在视网膜上。
这些光线携带了物体的立体信息,而人两只眼睛接受的光线位置和方向不同,会产生双目视差、移动视差、聚焦模糊等现象,我们的大脑可以从中获取到苹果的深度信息,最终让我们感知到一个立体的苹果。
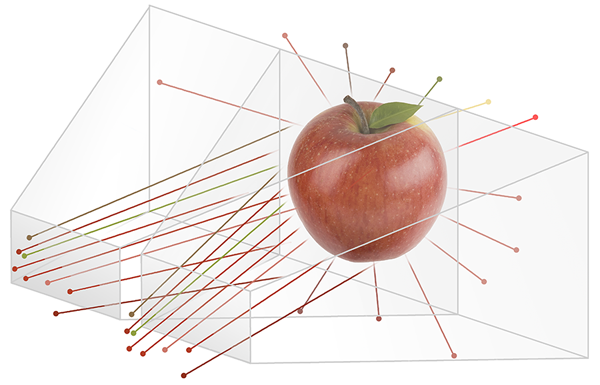
而相机等传统的影像采集设备,捕获图像的过程与我们的眼睛一样,是通过凸透镜成像系统将三维空间内经过视野范围的光线汇聚到感光元件上。但单镜头的相机只能记录光线的颜色,当感光元件上成像的一刻,光线便失去了所有的方向信息,成为了三维空间在二维感光平面上的一个投影。当然,无法记录方向信息,光场也就无从谈起。
既然现实中不存在可以直接采集光场信息的设备,那还研究这些干嘛?连最基本的光场采集都搞不定,光场显示岂不是更没指望?
别急,直线搞不定,咱们可以搞「曲线救国」,虽然没有直接采集的设备,但是传统的相机经过一番魔改还是可以完成这一艰巨任务的。从Lytro、Raytrix和OTOY等公司推出光场相机来看,现阶段的光场采集设备主要有两个方案:相机阵列和微透镜阵列。
相机阵列方案,大力出奇迹
高中老师曾经说过,「答题时要先看题目问的什么,带着问题去读题干,答案都在题干里。」
作为一名好学生,我表示这个方法确实屡试不爽。我们这次也先不去谈艰涩难懂的设备原理,而是反其道而行之,「少啰嗦,先看东西」。

这是什么?百度说这叫集束手榴弹。好吧,图片放错了,不过相机阵列方案确实和集束手榴弹有异曲同工之妙。
集束手榴弹的理念很简单,一颗手榴弹解决不了的问题就用两颗,两颗还解决不了就用一捆,简单粗暴,直接有效。相机阵列方案也是一样,通过增加镜头数量来记录光场信息,几十个甚至上百个镜头也是很壮观的有木有!

那么为什么相机阵列方案要做成这样暴力扩充规模的形式呢?做成这样怎么就能记录光场信息了呢?让我们将这个问题带入上面介绍的成像原理中来看看。
在普通的成像系统中,如果我们把镜头透镜看成(x,y)平面,把透镜中心看做平面中心(0,0),把感光元件所在平面看成(θ,φ)平面,那么拍出的照片可以看成是从x=0,y=0出发的光线在感光元件平面上的采样。也就是说我们采集了通过(0,0)点射向(θ,φ)平面的所有光线,不同的θ和φ对应着感光元件的不同像素。
如果我们移动(0,0)这个中心,让镜头在(x,y)平面上的每个位置都做一次采样呢?这不就相当于采集了整个(x,y)和(θ,φ)间的光场么?
So easy,妈妈再也不用担心我的学习了!这也正是相机阵列方案的核心思想。
相机阵列方案的实质,就是在(x,y)平面的不同位置对(θ,φ)平面进行采样,最终生成的图像则是在(x,y)平面的某一个观察点看到的画面,我们可以把光场看做是一个场景的一批视图,这些视图是从一个二维平面上的紧邻视点拍摄的。

如果这些视点分布的足够密集,间距足够小,便可以等效覆盖了整个(x,y)平面;而如果每个视点的视场角也足够大,那么就可以认为这个视点阵列能够采集来自(x,y)平面每个点、向(θ,φ)平面每个方向传播的光线,即是整个场景的光场。

一个16*16相机阵列,相机间距10cm,视场角90度,采集近2.7亿条光线
显而易见,(x,y)视点越多越密集,则采集光场信息的准确度越高。相机阵列方案可以做到很大的物理规模,轻松捕获几千万甚至上亿条光线,最终合成非常逼真的高分辨率图像。
当然,庞大的规模也同时是相机阵列方案的缺点:对系统的组装、移动都提出了很高的要求,而且相机阵列捕获的数据量同样庞大,对后期处理以及压缩和传输带来了很大挑战。
微透镜阵列方案,拒绝玄幻
基于微透镜阵列方案设计的光场相机,其内部有一个微镜头阵列被放置于相机主镜头的焦点所在平面,感光元件位于微镜头后面。每个微镜头后方均覆盖了感光元件的一部分像素,这些像素被称为一个「宏像素(micropixel)」。
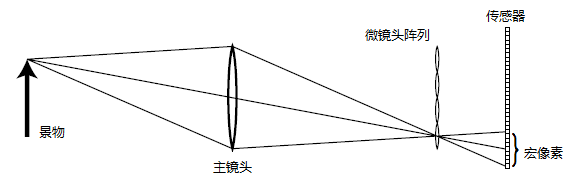
这个结构看起来比相机阵列要玄幻一些,我们还是用同样的问题来切入:微透镜阵列方案又是怎么采集光场信息的呢?
不要被表象所迷惑,如果我们把示意图中主镜头左边的部分挡住,我们就会发现,微透镜阵列方案的原理可以说与相机阵列方案如出一辙,就像下面这个样子:

这不就是一个迷你版的相机阵列方案嘛,每个微透镜以及后面对应的宏像素都相当于相机阵列中的一个相机。来自景物的光线进入主镜头后,从不同方向投射到位于主镜头焦点处的微镜头阵列,并映射到微透镜后面的宏像素上。这些宏像素便相当于相机阵列方案中的视点,宏像素的坐标便对应着光线的几何位置,而宏像素中包含的每个像素则代表成像物体不同视角的信息。
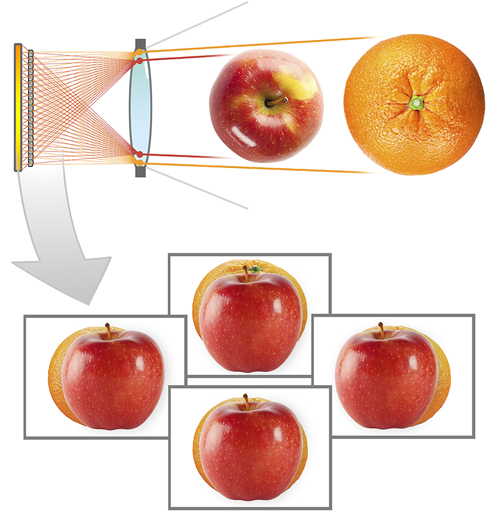
微透镜阵列方案可以在常规相机结构的基础上进行改进,推出家用的小体积光场相机。而且微透镜阵列相机的总像素数比相机阵列更少,生成的数据量也相应的要小很多,对储存和传输来说无疑是一个重大利好消息。
但微透镜阵列方案的也有一些缺点。首先,由于感光元件的总像素数有限,如果每个微透镜覆盖的像素多,相当于将更多的像素资源用于记录光线的方向,最终图像的分辨率就低。Lytro创始人吴义仁(Ren Ng)在2005年制作的光场相机,使用的是1600万像素数码机背,但最后输出的图像只有296×296分辨率,还不到9万像素。

这张照片很有名,但谁能想到它的分辨率只有296*296呢?
第二,微透镜阵列的结构等效于在相机阵列之前加了一个主镜头,所以主镜头的光圈必须要大,这样才能保证光场中每一条光线的差异性。而且主镜头的光圈、焦距发生变化后,后期合成中就需要设置不同的参数,所以目前微透镜阵列相机的对焦距离会有一定限制,微距和远景的成像不是特别理想,变焦倍数也不会很大。
第三,透镜成像的过程中会产生像差,微透镜阵列方案需要主镜头和微透镜两套透镜,光线两次通过透镜会让像差加剧放大,不但难以矫正,而且会影响光场信息的准确性。
现在,光场的采集已经解决了,接下来的问题是,拍出来的东西我们怎么看?
拍出来是要给人看的
看完上面那两个方案,我们心里都应该有数,它们拍出来的东西肯定是非比寻常。拍了之后直接拿来看这种念头根本想都不用想,看了它们拍的原图后,你一定会瞬间想到一句歌词,我打包票。

借我借我一双慧眼吧,让我把这纷扰看得清清楚楚明明白白真真切切……
当然,你能拆就得能砌,能拍也得能看才行。人看不明白不要紧,办法总是有的,能解决这个问题的就是劳苦功高的计算机,它替我们将这些记载着光场信息的图像进行处理,还原为我们能直接观看的形式。
解决问题的过程当然很复杂,其中要涉及到开篇时提到的数学公式,什么傅里叶啥啥和欧拉啥啥的。这里我们不讲那些高深的处理算法,只用一个动图就能向大家表达光场处理的实质:叠加。

没错,光场处理的实质就是叠加。光场相机拍摄的图像记载了从每个视点观察到的N条光线,就和初中数学里根据左视图、主视图和俯视图推导几何体形状差不多,计算机可以将这些视点叠加融合,重新构筑出场景的四维光场。
然而,虽然拍摄的过程不至于像初中几何题那样只有粗糙的三视图,但相机的物理结构毕竟存在制约,无论是相机阵列还是微透镜阵列,视点都不可能无限多无限密集,那两个视点中间的部分怎么办,难道重新构筑出来的四维光场是不连续的?这样的话,最终输出的图像就会有各种重影和边缘发虚的问题了啊?

其实这种不连续并不可怕,只要使出「插值」大法便可解决问题。就像我们知道0和1之间还有0.1~0.9这些小数一样,既然计算机已经重新构筑出场景的四维光场,那么只要借助场景的深度信息,在相邻两个视点的图像之间运用插值算法,就能生成一个虚拟视点上的插值图像。
通过这种插值,可以让视点更密集,密集到两个相邻视点图像上对应像素的位移都小于等于一个像素,从而在视觉上消除这些因为采样不连续而造成的异常现象。
不过,插值只是一种后期补偿手段,想要获得良好的光场效果还是要保证足够的前期采集量。插值算法本身就是不精确的,如果原本采集的光场信息过少,过度插值会让最终还原出来的光场变得更糟。「开局两张图,中间全靠插值」是肯定不行的。
光场显示,元芳你怎么看?
讲完了光场的采集和处理过程,现在终于到了最后一个步骤,光场显示,也就是怎样将结果呈现给我们看。
其实在经过上一步的处理之后,最终输出的结果已经可以在传统2D显示设备上呈现了,但这样所表现的显然不是完整的光场,只是光场中的一个切片而已。不过依靠光场信息,我们也可以在2D显示设备上玩出一些以前平面影像实现不了的花样,比如重聚焦和视点变换等。
真正的四维光场成像,毫无疑问就是开篇提到的「魔法之跃」啦~开个玩笑,这个在体育馆内展示的鲸鱼,Magic Leap早就承认过是特效制作。不过这并不代表Magic Leap就是个靠CG蒙吃蒙喝的骗子,目前的几种四维光场成像方案中,比较有代表性的就有Magic Leap的光纤投影成像,以及美国南加州大学的多投影阵列和由微透镜阵列方案逆向而来的「微透镜投影成像」。
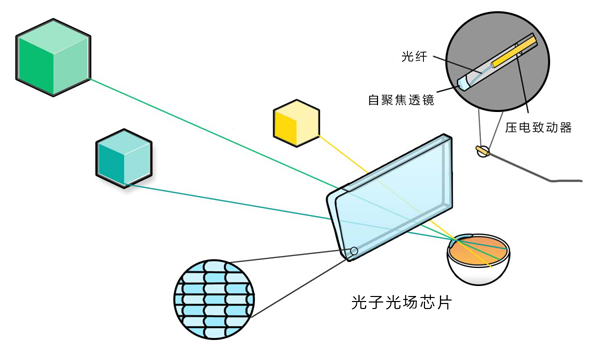
Magic Leap研制中的光场眼镜,使用眼镜侧面的光纤扫描投射器发出光线,同时其镜片是一种被称为「光子光场芯片」的特殊光学元件,内膜上衬有大量微型曲面镜片,可以把图像以设定好的深度在真实世界中对焦。光子光场芯片很薄,可以堆叠多层,在不同的深度上显示不同的「切片」内容,实现真正的光场显示。
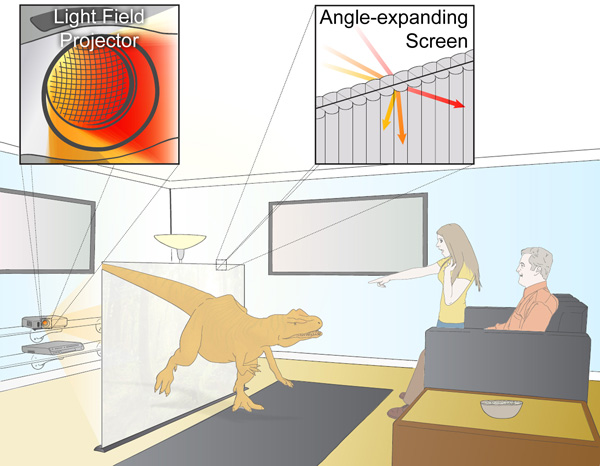
另一种光场显示方案是多投影阵列技术,美国南加州大学在2016年CVPR上展示过可实现1:1真人的裸眼光场显示系统,该系统包括216个投影仪和6台PC主机,占地一个房间大小。此系统不需要佩戴特殊眼镜且能满足多人多角度观看,因此需要大规模的投影仪阵列来增加FOV,带来了巨大的计算压力,其计算量是传统2D图像的数倍。

而「微透镜投影成像」则是我自己起的名字,因为它由微透镜阵列方案逆向而来。如果我们把微透镜阵列方案本末倒置一下,将感光元件变成显示屏或投影仪,微透镜置于前方,发出的光线经过微透镜折射后进入人的眼睛。由于光路具有可逆性,这样就逆向还原了拍摄时捕获光线的路径,也就是还原了光场。
- 结语 -
其实和之前盘点移动处理器的时候一样,光场采集方案除了相机阵列和微透镜阵列之外,还有掩膜及其他孔径处理方案。不过鉴于理论资料和实际应用都很少,我们这次便只拿相机阵列方案和微透镜阵列方案开刀,让掩膜及其他孔径处理方案躲过一劫。

值得一提的是,第二代Lytro ILLUM的4100万像素对于微透镜阵列方案来说只是刚刚入门,实际输出的光场照片只有400万像素,勉强达到可冲印的需求。而且负责制定图像标准的JPEG小组还没有推出光场图像的通用格式,几家厂商都在使用各自不同的算法和格式,这无疑会对光场影像的传播造成很多不便,不利于民用级光场相机的普及。
基于这些考虑,Lytro在11月30日停止了对Living Picture 图片播放插件的支持,并关闭了官网的图片浏览网页pictures.lytro.com。他们将暂停民用级光场相机Lytro ILLUM系列,在未来一段时间内专注于工业级光场相机的开发。

总体来说,无论是前期采集、后期处理以及最终的显示,有关光场的技术原理已经得到充分的验证,剩下的只是设备性能、可制造性以及通用标准相关的问题。毫无疑问,光场设备在未来一定会大放异彩,为我们带来革命性的视觉体验。
推荐阅读





