能变脸还能换身材!Facebook新研究将在AR/VR实现全身追踪
发布时间:2018-01-29 10:10 来源: 芬莱科技
现有的计算机视觉技术工具中,大多是利用实时的面部识别技术,结合贴图的使用,可以实现一键美妆或者换头、变成各种卡通头像等功能,但可以用化身替代整个身体来进行AR操作的技术还是比较少见的。最近,Facebook团队开发了一种新的技术,可以准确地检测到身体姿势,同时将人体从背景中分割出来,之后再处理分割出的人体,就可以做到我们前面提到的“换身术”的操作。

要实现对人体建立的AR,就需要实时并准确地检测和追踪身体动作。这其实是一个非常具有挑战性的问题,因为身体姿势和动作变化会很大,比如一个人可能坐着,也可能走着或是跑着,而且有时候人的身体还会被他人或物体阻挡。这些因素都大大增加了身体追踪系统保持稳定性的难度。

为了解决这些问题,Facebook的研究团队采用了Mask R-CNN框架,这是一个由Faster R-CNN延伸而来图像语义分割框架,不仅简单、灵活,且十分通用。它可以高效地检测图像中的对象,同时预测关键点的运行轨迹,并为每个对象生成一个分割掩码。通过Mask R-CNN框架,就可以识别图像中的人体动作。
Mask R-CNN框架的构建方法是:在每个兴趣点(RoI)上加一个用于预测分割掩码的分层,称为掩码层,使该层并行于已有边界层和分类层,于是,掩码层就成为了一个小型FCN。我们将它应用于单个RoI中,以在pixel-to-pixel行为中预测分割掩码。
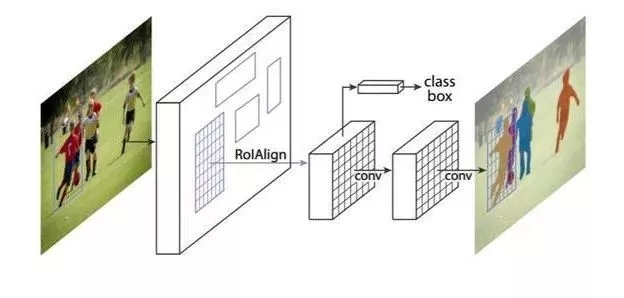
Mask R-CNN 有很多优点,由于目前已有许多设计良好,可用于Faster R-CNN的构架,因此,作为Faster R-CNN的延伸,Mask R-CNN在应用时也没有阻碍;考虑到掩码层只给整个系统增加一小部分计算量,所以该方法运行起来非常高效;Mask R-CNN 还可以很容易泛化到其它任务上。比如,可以在同一个框架中估计人物的动作。

在COCO测试中可以看到,Mask R-CNN 在实例分割、边界框目标检测和人物关键点检测这三个难点上都获得了很好的实验效果,比每个现有的独立模型,包括 COCO 2016 挑战赛的获胜模型,表现都要好。


而在最新的论文中,由于手机等移动设备的计算能力和储存空间有限,Mask R-CNN不能支持在这种设备上的使用,所以为了在移动设备上实时运行 Mask R-CNN 模型,Facebook 团队的研究人员和工程师在Mask R-CNN的基础上构建了一个高效而轻量的框架模型:“Mask R-CNN2Go”。
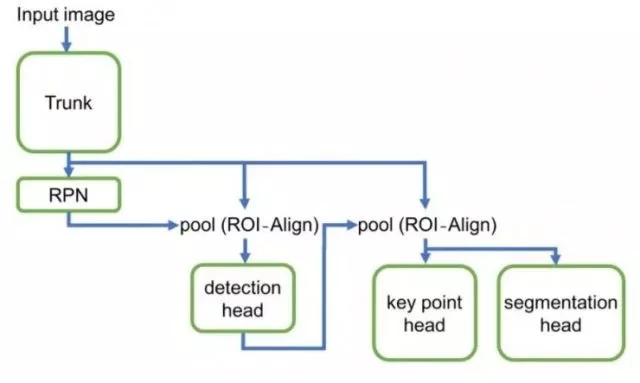
Mask R-CNN2Go 模型由五个主要组件组成:
主干模型包含多个卷积层,并且生成输入图像的深层特征表征。
候选区域生成网络(RPN)以预定的比例和纵横比(锚点)生成候选对象。OI-Align 层从每个对象的边界框中提取其特征并将它们发送到探测端。
探测端口包含一组卷积层,池化层和全连接层。它能预测每个候选框中的对象有多大可能是一个人体。探测头还可以改进边界框的坐标,将非极大抑制值的相邻框候选框进行分组,并为图像中的每个人生成最终的边界框。
利用每个人的边界框,我们使用第二个 ROI-Align 层来提取特征,这些特征来自于关键点端口和分割端口的输入。
关键点端口与分割端口具有相似的结构。它为身体上的每个预定关键点预测出一个掩码。并使用单一最大扫描来生成最终坐标。
Mask R-CNN2Go 的架构图
与 GPU 不同,手机的算力和存储空间都十分有限。如前所述,Mask R-CNN 最初的模型是基于 ResNet的,太大而且太慢,无法在手机上运行。为了解决这个问题,Facebook研究团队使用了几种方法来减小模型的大小。首先,为了减小原有的Mask R-CNN模型的大小,研究团队优化了卷积层的数量和每层的宽度,而为了确保拥有足够大的感受野,新的Mask R-CNN2Go模型使用了包括1×1,3×3和5×5的内核大小的组合。另外,研究团队还使用权重剪枝算法来缩减模型。最终的Mask R-CNN2Go模型只有几兆字节,但是仍非常精准。
另外,为了能够实时运行深度学习算法,研究团队优化了核心框架,而且由于使用移动 CPU 和包含 NNPack,SNPE 和Metal在内的GPU库,因此Mask R-CNN2Go移动计算的速度显著提高了。这些都是通过模块化设计完成的,并不需要改变模型的一般定义。因此,Mask R-CNN2Go模型不仅大小很小,又可以获得较快的运行时间,同时还避免了潜在的不兼容问题。
Facebook研究团队在博客中表示,他们将继续探索新的模型架构,力求进一步提升模型效率,并且还将探索更适合移动 GPU 和 DSP 的模型,让它们更加节省电量和算力。而未来,在此基础上可以识别全身的AR应用必定层出不穷。
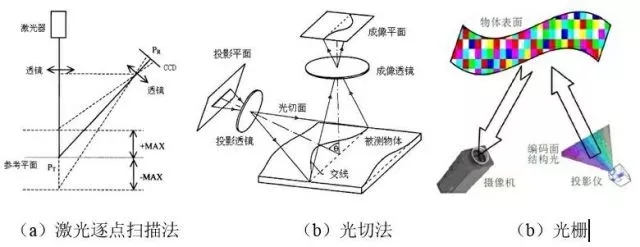
需要注意的是,很早之前微软的Kinect也可以做到动作识别,但它与Facebook的方案是完全不同的。微软的Kinect主要是利用近红外激光器向对象物体投射复数个不规则排列的点光源图案,并利用摄像头捕捉投影在对象物体上的图案。然后,求出捕捉到的图案的摄像头视角。之后,以此为基础,计算出与对象物体之间的距离,从而识别人体的动作。而Facebook的方案则是单纯的对摄像头得到的图像进行分析和识别,并不需要额外传感器的使用,更适合在手机等移动设备上应用。
微软Kinect原理图
Facebook完成的动作识别技术并不算新颖,它的创新点在于它采用了新的Mask R-CNN方案,只占用极小的内存而且有极高的效率,这就让它可以更好地应用在智能手机上。如果有同学对此有兴趣,可以在链接https://research.fb.com/enabling-full-body-ar-with-mask-r-cnn2go/ 中下载论文,或者在https://github.com/facebookresearch/Detectron中下载代码。
推荐阅读





