Oculus发布官方博文:揭秘VR中的近场3D音效技术
发布时间:2017-09-28 11:10 来源: 雷锋网

双声道3d立体声的原理是通过为左右耳朵提供基于声源3D位置的经过特殊“滤波器”处理的声音而实现的。术语“滤波器”可用于描述从小到简单均衡器EQ,大到复杂混响的所有相关事物。那么我们接下来说什么呢?
正如混响滤波器通过双通道脉冲响应(IR)的方式,捕获的声音可以在到达听众耳朵的途中与周围环境进行交互,而双声道空间环绕滤波器捕获的声音可以在到达听众耳朵的途中与听众的身体进行交互。
在混响的情况下,由于环境的大小和复杂性,脉冲响应IRs时间较长而且秩序混乱。多年来,我们一直在利用这个优势,以单一的双声道混响脉冲响应IR来模拟近似的环境,因为声音脉冲响应经过了最初的几次反射后,空间感逐渐削弱,最终完全消失,使得我们无意识地认为听到的声音就是与我们的周围环境融在一起的。
在双声道3D空间立体声案例中,脉冲响应IRs很小,但是极其具有方向性。即便超过几英尺的距离,脉冲响应IRs也不会有很大变化。我们一直在利用这一点,对3D立体声音频进行另一种近似模拟,这种技术与距离无关,我们称之为“远场”。我们的HRTF数据库在头部如同一个有序的球型网格空间内进行捕获/采样,而不是堆在一起。

我们沿方位角和仰角空间化,而不是沿距离方向。
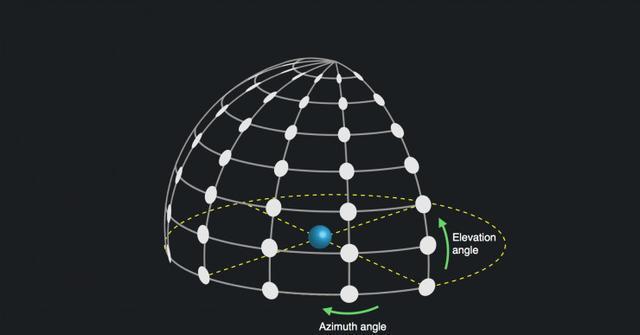
距离在单独的专用模型中解决:
高低频衰减曲线
介质吸收滤波
处理/原始音频信号平衡
近场渲染技术的理论基础是,当从听众的距离缩小到与人类头部的大小相当时,该模型不起作用。在这种情况下,空间化和距离建模变得密切相关,并且在从以耳为中心的参考空间内,要比以头为中心的空间合成效果要好。在远场,声音世界的中心是以我们的头部为中心。而在近场,声音世界的中心是耳道入口,我们有两只耳朵,这使得近场比远场更为“双通道”。
近场距离(围绕听者头部的近场球体的半径)通常定义为约0.5 - 1.0 m(或3英尺,“在一臂的距离范围内”)。我们目前的远场HRTF技术的演变是通过向数据库添加更多的滤波器样本(红点)将其扩展应用到近场之中,以将整个近场球型空间与头部边界之间的所有空隙填满:
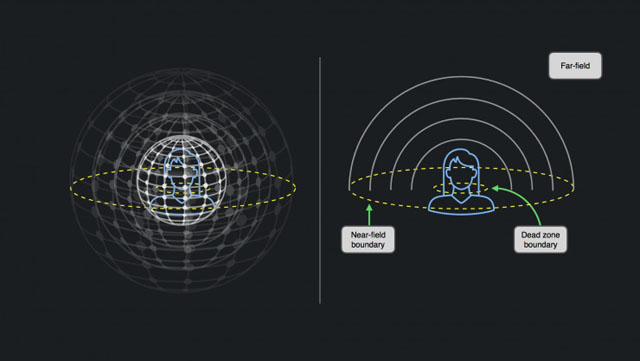
这种方案可能会降低R&D的水平,但同时也需要占用更多的硬件资源。同时,就像混响和远场空间化案例一样,我们正在寻找一种在有限资源的硬件上快速运行的能取得相似效果的方案。
那么近场音频有什么特别之处?
对于我们的近似模拟工作,我们首先必须确定近场渲染的主要感知线索:
越来越近,意味着自由场中的平方反比律更大。
但是响度增加主要表现为ILD(双耳声级差),因为头部对声音传播的干扰,声音可以比另一只耳朵更接近一只耳朵,从而产生比远场更高的ILD。
增加头部阴影/衍射:在相反(遮挡)侧,高频比低频衰减更多。
总体而言,在增加的ILD之上,能带来微妙的低音体验提升。
原始信号:开始的声音反射和漫反射会给人带来强烈的距离感,因此必须控制在最小水平。
由此,这种近似模拟将在侧面位置(远离中间平面)带来更好的效果,在这个位置ILD和环绕滤波器效果最强,并且我们需要完全控制反射信号增益(前期反射和后期混响)。
还值得注意的是缺少ITD(Interaural Time Difference,双耳时间差)特定的线索:较近的距离不会以可感知的方式影响每个耳朵之间的时间差异,但是确实要比它们忽远忽近的移动时,会产生更大的ITD和ILD变化(例如晚上那个讨厌的蚊子!)。
近场渲染模型
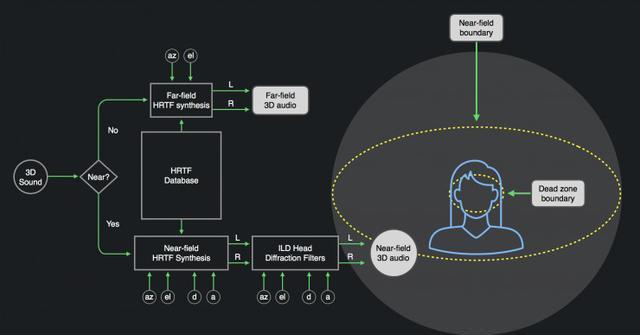
az:方位角
el:仰角
d:到聆听者的声音距离
a:头直径
第一步采用我们的远程HRTF数据库(像往常一样),但是从两耳而不是头部中心的几何空间内重新解释它。
下一步是像往常一样卷积我们的源信号,但现在结合上我们刚刚建成的近场HRTF。在这一点上,我们已经补偿了HRTF查找中的方向误差,因此空间化更准确,但是由于我们使用远场HRTF,我们仍然听起来有种很“远”的感觉。
最后,我们应用实时头影效应的物理建模。
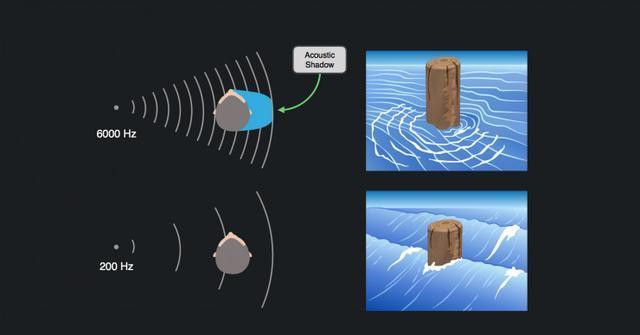
这里发挥的关键物理现象是声学衍射:围绕刚性障碍物,如头部,产生的声波弯曲。
这种现象是频率依赖的:
低频可以绕障碍物弯曲
高频不能
截止频率取决于障碍物的大小
这可以认为是双耳(每个耳朵会得到不同的滤波效果)定向低通滤波器,截止频率与头部大小,方位角和仰角直接相关。其中一些滤波已经被捕获在我们的远场HRTF(头衍射不仅仅限于近场使用),所以我们使用一组在距离,方位角和高度参数化的实时滤波器来微调效果。
以下为涵盖立体声效技术(Volumetric Sounds)及通过各种声学设计实现更好的聆听效果
使用HRTF的空间音效(Spatial sound)对于表现点源是非常好的,这是它的设计目的,你可以通过点源获得很好的效果。然而,在现实世界中,并不是所有的声音都来自于空间中的某一点,有时候你希望的声音来自于更大的发声空间。当听众附近有一个较大的物体或对象时,这一点尤其如此。在这些情况下,使用点源可能听起来不那么自然,就像声音只来自对象的中心。
工作环境
有一些办法可以解决点源问题,但各有自己的优点和缺点。一种常见的方法是混合一些原始信号以减少方向性,这通常被称为“扩散(spread)”或“2D混合(2D blend)”。这种方法来自传统的游戏音频解决方案,其中通过平移实现音频空间化,做法是混入原始信号用来柔和平移中产生的刺耳噪声以实现声音环绕感。但这种方法在基于HRTF空间化的VR中,不起作用的。具有HRTF的3D空间化包括两耳时间差(ITD),模拟双耳的声音延迟也被加入到了信号之中。当延迟的空间化信号与原始输入信号混合时,由于延迟,可以产生梳状滤波伪影。
另一种方法是用很多点源发声。这种方法可以合理地工作,但这将涉及发声源数量安排,你需要为声源数量找到恰当的平衡。如果多个源产生完全相同的信号,那么会有潜在的相位相干性问题。
Volumetric Sounds
为了获得更大的声音,Oculus研究人员开发了一个基于距离和半径来计算投影的过程,并在运行时构建空间滤波器。当声音很远时,投影很小,听起来像点源。当声音靠近收听者时,投影更大,声音变得更宽广浑厚。
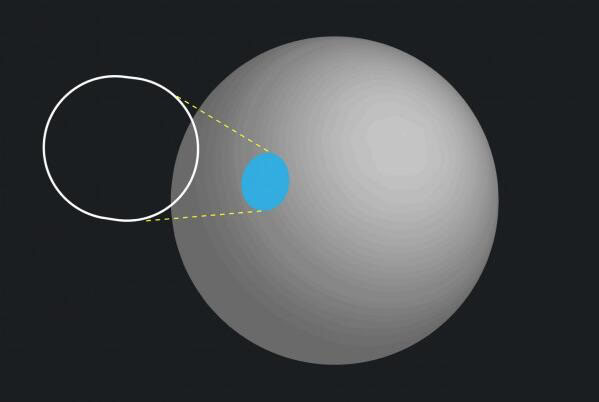
图1:球体听众空间上具有小投影面积的遥远声音

图2:球体听众空间上具有较大投影面积的更接近的声音
这提供了一种实际上正确和高性能的方式来模拟大型声源。当听众在声源的半径内时,他们会被声音包围环绕。随着听众接近声音的中心,它从空间声音顺利地过渡到环绕声。
这种新技术类似于图形社区在全球照明和光传输问题上所做的工作。主要思想是使用像立体函数这样简洁紧凑的基础功能来表示球体上的光滑函数,如漫射照明。该基础表示法具有双重优点:(a)它节省了内存(b)它将复杂的积分表达式简化为简单的向量点积计算。这能够实现对大型复杂虚拟环境的漫射照明和全局光照明的实时计算。
这里的基础技术是球面调和函数理论,也是实现立体声的基础,但对于大体积声源,它的应用略有不同。HRTF滤波器存储在球面谐波域中,这使得我们可以计算点源的滤波器或球体听众空间的任何形状的投影。最初可以应用于球状发声体,这是通过投影到球型听众空间上的圆形投影来计算HRTF滤波器的。
大型音源允许声学设计师对物体进行大型建模和小型建模,它基本上是分散于空间音频上。值得强调的重要一点,大型音源的作用只是将声音传播出去,而不是提供一种规模感。借助混响平衡和混合动力这样的方法,让声音听起来“大”仍然是声音设计师的工作。最后,Volumetric仅是工具带中的一个能得到准确混合结果的额外工具而已。
推荐阅读





