详解VR定位技术:如何在虚拟世界中自由移动?
发布时间:2017-09-28 11:14 来源: 87870
空间定位是VR 市场中一个非常关键的技术,当今排名前列的VR硬件设备厂商(HTC Vive和Oculus)分别采用了不同的空间定位方案:
Oculus——Constellation红外摄像头定位
HTC Vive——灯塔激光定位系统
尽管这两种定位方式都采用了PnP解算,但都有各自的局限性和适应的场景,下文将逐一详细分析。
丨Oculus Constellation定位系统
Oculus采用的是基于Camera的定位方案,被称为Constellation。在Oculus头盔和手柄上都布满了红外Sensor,以某个固定的模式在闪烁。

通过特制的Camera以一个固定的频率(Oculus RiftCV1是60fps)拍摄,得到一组图片。系统通过这些点在图片上的二维位置,以及已知的头盔或者手柄的三维模型,反推出点在三维空间中的位置。这个过程可以进一步的细分成以下的步骤:
首先,为了确保准确的定位到头盔和手柄上的LED,PC端的Oculus Camera软件/驱动程序通过HID接口发送某个命令点亮LED,该亮度足以被Camera捕捉到,同时这些LED以某个特殊的模式闪烁。这样能确保即使有遮挡的情况下,在不同的角度下,只要有足够多的LED被拍摄到,整个的tracking系统就能正常工作,不会被环境中的其他噪声信号所影响。
然后是记录下每一个被捕捉到的LED的位置和方向。
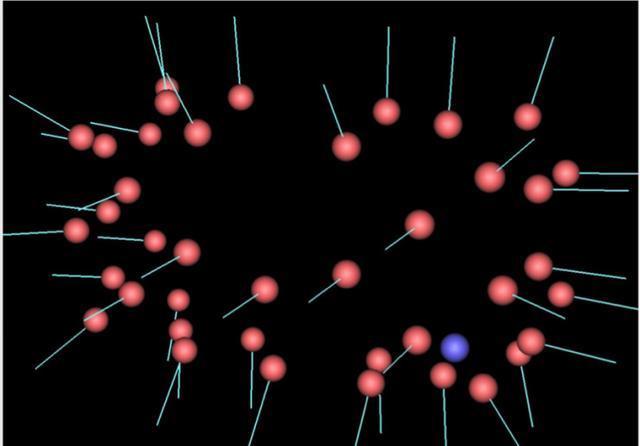
当然,为了做好定位,Oculus Camera本身并不需要LED的颜色,只需记录每个点的明暗,所以Oculus Camera固件中记录下的的图像为752×480像素, 像素格式为Y8灰阶,每一幅图看起来如下:

拿到头盔上的LED在二维图片上的位置,又有头盔上Sensor的三维模型,有什么办法可以估算出这些点的三维位置?这本质上是一个Pnp解算的问题(https://en.wikipedia.org/wiki/Perspective-n-Point):有了n个3D点的模型(就像上面提到的LED点在头盔上的3D分布), Camera拍摄下来的n个2D点的集合,再加上Camera本身的内部的参数,可以推算出这些点的位置坐标(X,Y,Z) 以及姿态(Yaw,Pitch,Roll)。
这个点的集合到底有多大?这是一个寻求最优解的问题,常见的做法是n>=3,也就是图片上只要拍到三个以上的LED,就能够解算出相关的姿态和位置。考虑到遮挡或者拍摄的照片不够清楚等因素,实践中看,至少要拍摄到4-5个点,整个头盔的姿态和位置才能被正确的算出,这也是为什么在Oculus的头盔上布满了很多LED点的一个重要原因。
算出来的数据有误差怎么解决?一个常见的办法是得到6DOF的数据之后,用该数据再做一次投影,产生新的2D图像,把该图像和我们开始用来计算的图像进行比较,得到一个误差函数,应用该函数来进行校准。不过这带来另外一个问题:点进行比较的时候,你怎么知道3d模型上的点,和拍摄到的二维图像上的点之间的匹配关系?如果做一一对应的全匹配计算的话,计算量太大。所以Oculus采用的办法是采用不同的闪烁模式,来快速匹配3d模型上的点和拍摄到的图像上的点。
进一步,在姿态估计的问题上面,通过光学(Camera图片)得到的姿态会有误差,而这种误差主要来自于物体快速移动时捕获到的照片上的点识别的困难。为了减少这种误差,需要通过IMU信息来进行一步校准通过PnP解算得到的姿态,这就是所谓的Sensor数据融合。
从上面的描述可以看出来,基于Camera的光学定位技术,安装配置比较简单,成本也比较低,但是图像处理技术较为复杂,物体移动较快时识别物体的位置有比较大的困难,同时容易受到自然光的干扰。
另外,基于Camera的定位精准度受到Camera本身分辨率的限制,比如Oculus Rift的Camera为720p,比较难以提供亚毫米级的精准定位。
最后,Camera自身能够捕捉到的照片的距离比较近,不能应用到很大的房间位置,一般都只能提供桌面级别的VR定位。当然最近Oculus提供了三个Camera的方案,试图在room scale级别和灯塔定位技术一较高下。
丨灯塔激光定位技术
反之,HTC等企业提供的灯塔激光定位技术,避免了Camera定位技术的高复杂度,具有定位精度高,反应速度快,可分布式处理等优势,能够允许用户在一定的空间内进行活动,对使用者来说限制小,能够适配需要走动起来的游戏,真正实现Room Scale级别的vr定位。
下面从灯塔定位的原理解释为什么在大空间的应用中灯塔激光定位是一个更好的选择。
HTC的灯塔定位系统中有两个基站,每个基站上面有两个马达,其中一个马达往水平方向扫射,另外一个朝垂直方向扫射。
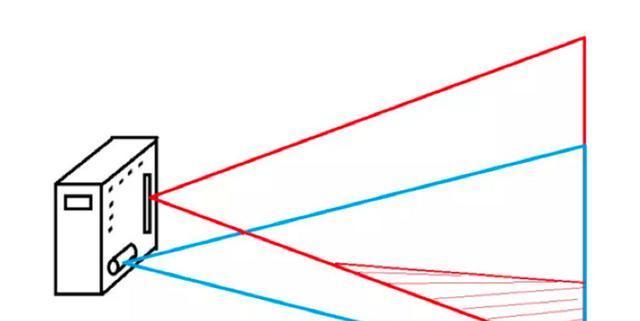
基站刷新的频率是60Hz,基站a上面的马达1首先朝水平方向扫射,8.33毫秒之后,第二个马达朝垂直方向上扫射(第二个8.33毫秒),然后基站a关闭,接着基站b重复和基站a一样的工作......
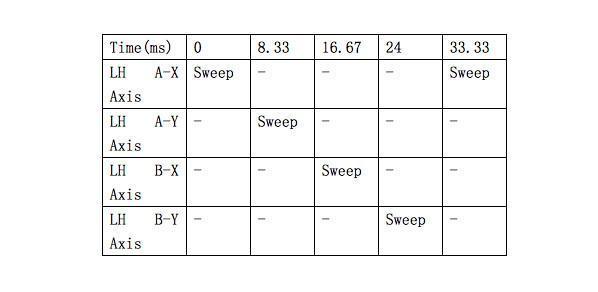
这样只要在16ms中,有足够多的Sensor点同时被垂直和水平方向上的光束扫到,这些Sensor点相对于基站基准面的角度能够被计算出来,而被照射到的Sensor点在投影平面上的坐标也能够获得。同时,静止时这些点在空间中的坐标是已有的,可以作为参考,这样就能够计算出,当前被照的点相对于基准点的旋转和平移,进一步的得出这些点的坐标,这其实也是一个PnP问题。
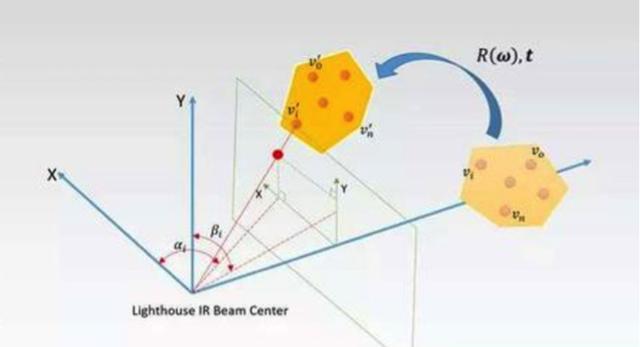
进一步的,再融合IMU上获得的姿态,就能够较准确的给出头盔或者手柄的姿态和位置。
在上一步中计算出来的头盔/手柄的位置和姿态信息,通过RF传递到和PC相连的一个接收装置,该装置再通过USB接口,把数据上传到PC端的driver或者OpenVR runtime,最后上传到游戏引擎以及游戏应用中。
推荐阅读





